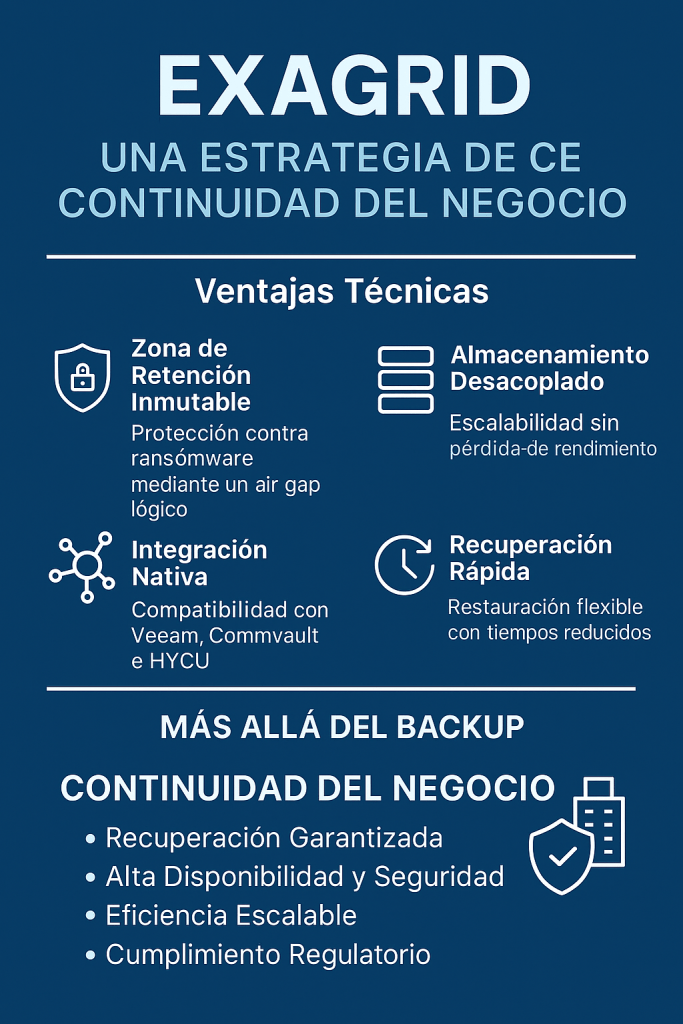
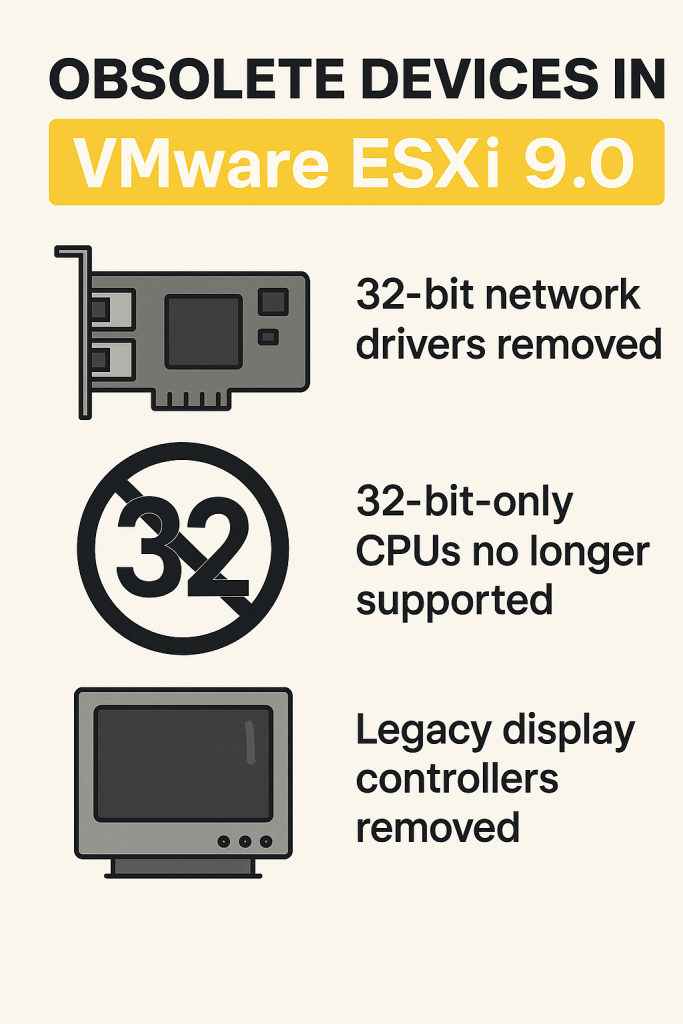
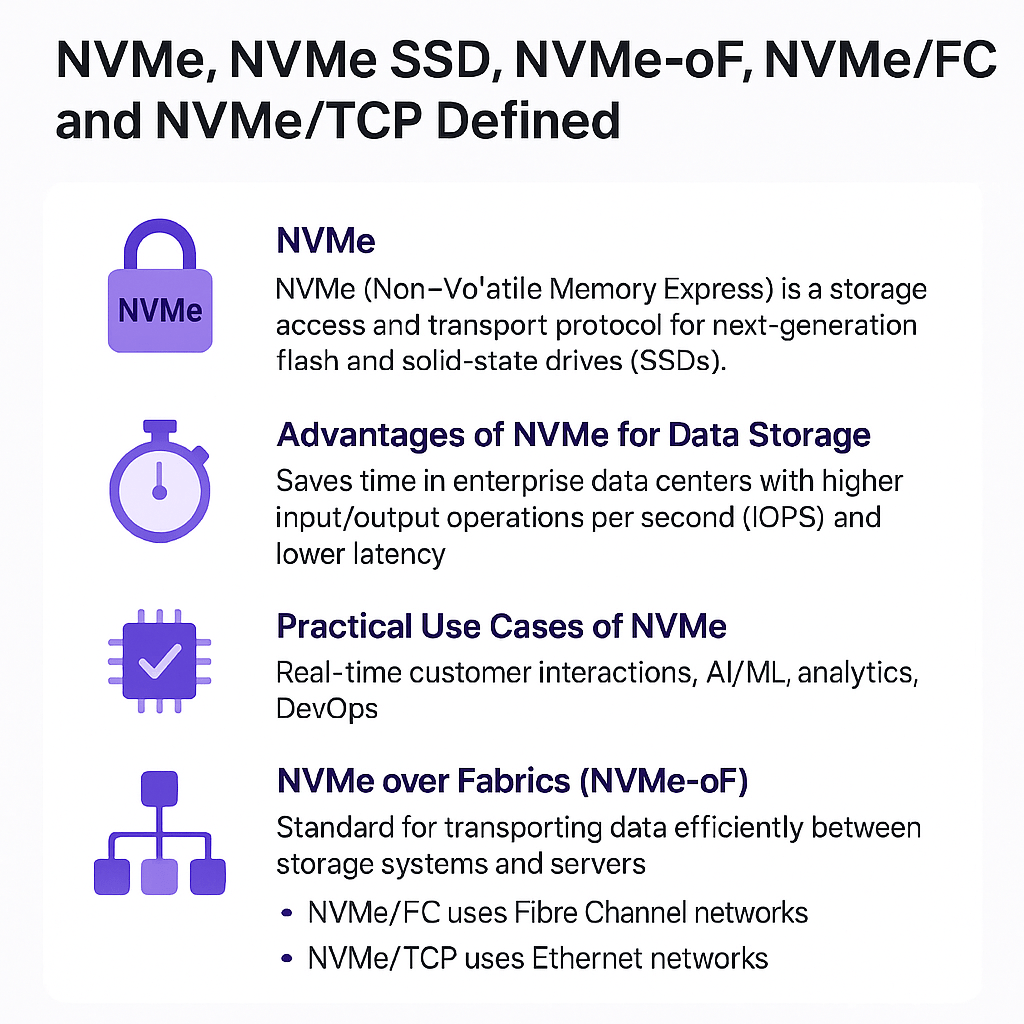
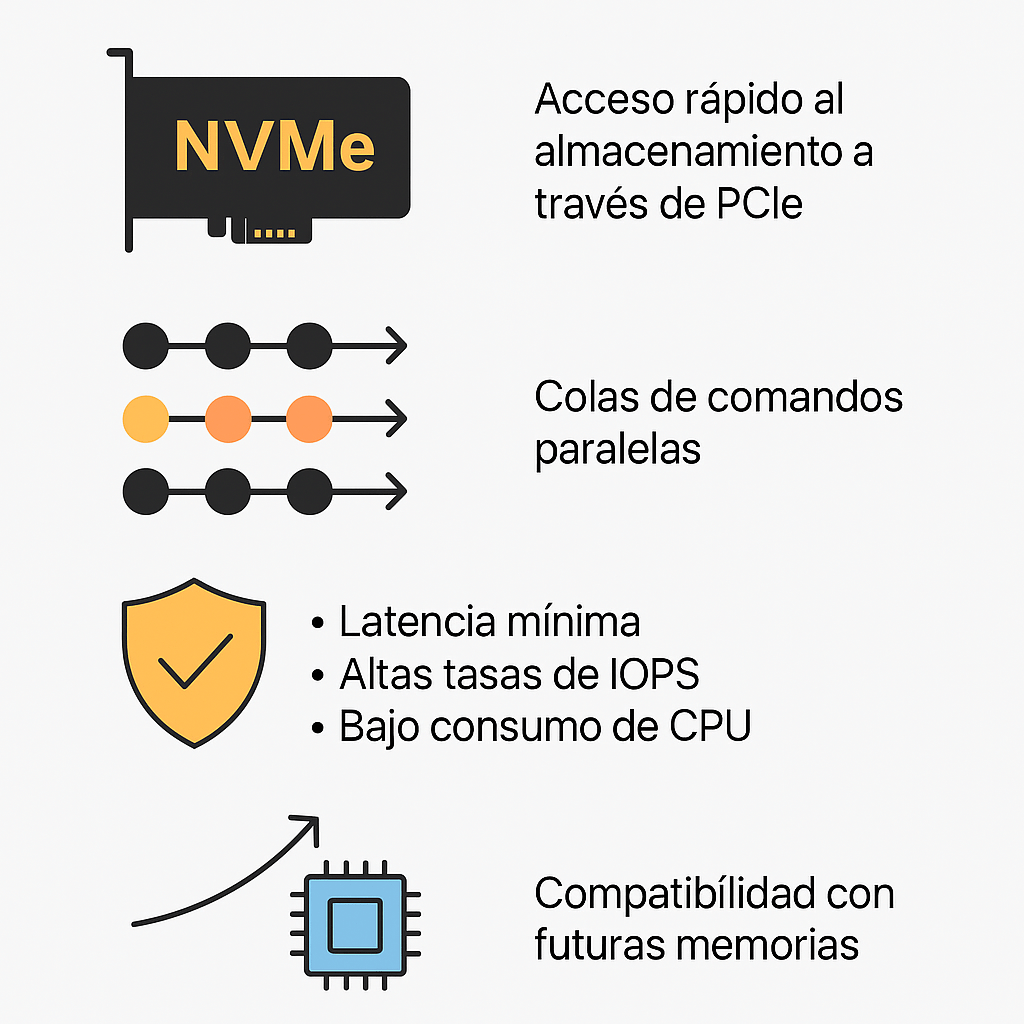
En la actualidad, la seguridad de los datos ya no puede considerarse una acción reactiva. Las amenazas evolucionan con rapidez y los entornos híbridos requieren medidas proactivas. Aquí es donde entra en juego el enfoque Secure by Design: una metodología que promueve la implementación de seguridad desde la concepción de los sistemas y procesos.

¿Qué es Security by Design?
Inspirado en industrias como la automotriz y la aeroespacial, el enfoque Secure by Design busca garantizar que las soluciones tecnológicas estén diseñadas desde el inicio con la seguridad como componente fundamental. No se trata de añadir protección después, sino de que esta esté integrada desde el diseño.
Los 8 principios clave
- Requisitos de seguridad definidos desde el inicio.
- Codificación segura, con auditorías continuas.
- Modelado de amenazas y análisis de riesgos como parte del diseño.
- Gestión de vulnerabilidades con escaneos periódicos y parches oportunos.
- Defensa en profundidad, mediante cifrado, MFA y segmentación.
- Valores seguros por defecto, evitando configuraciones débiles.
- Monitoreo y registro constantes, integrados a plataformas SIEM.
- Protección de datos cifrada, tanto en tránsito como en reposo.
Aplicación práctica en la protección de datos
Cuando se trata de proteger datos, estos principios cobran aún más relevancia:
- Confidencialidad a través del cifrado y acceso restringido.
- Integridad, asegurando que los backups no puedan ser alterados.
- Disponibilidad, garantizando una rápida recuperación tras incidentes.
¿Qué beneficios ofrece a las empresas?
- ✅ Menor exposición a riesgos
- ✅ Cumplimiento normativo más simple
- ✅ Reducción de costos a largo plazo
- ✅ Mayor confianza por parte de clientes y stakeholders
Veeam y su enfoque Secure by Design
Veeam adopta este modelo como base de sus soluciones. Desde configuraciones seguras por defecto hasta prácticas colaborativas con la comunidad de ciberseguridad, su plataforma garantiza que los datos estén protegidos de forma integral. La arquitectura permite aplicar controles RBAC, cifrado extremo a extremo y herramientas de monitoreo adaptadas a entornos híbridos y multicloud.
Conclusión
Implementar seguridad desde el diseño no es solo una buena práctica: es un diferenciador competitivo. En tiempos donde los ataques son inevitables, la resiliencia es lo que separa a una organización preparada de una expuesta.
📌 ¿Listo para implementar una estrategia Secure by Design?
Descubre más sobre cómo Veeam te puede ayudar a proteger tus datos desde el diseño.